Прорыв из изоляции: способны ли ИИ-агенты покинуть свои песочницы?

Контейнерные песочницы являются стандартным инструментом для тестирования и развертывания ИИ-агентов. Агенты используют их для выполнения кода, редактирования файлов и взаимодействия с системными ресурсами без прямого доступа к основной системе. Бенчмарк SandboxEscapeBench, разработанный исследователями из Оксфордского университета и Института безопасности ИИ, оценивает способность агента с доступом к оболочке вырваться из контейнера и достичь хостовой системы.
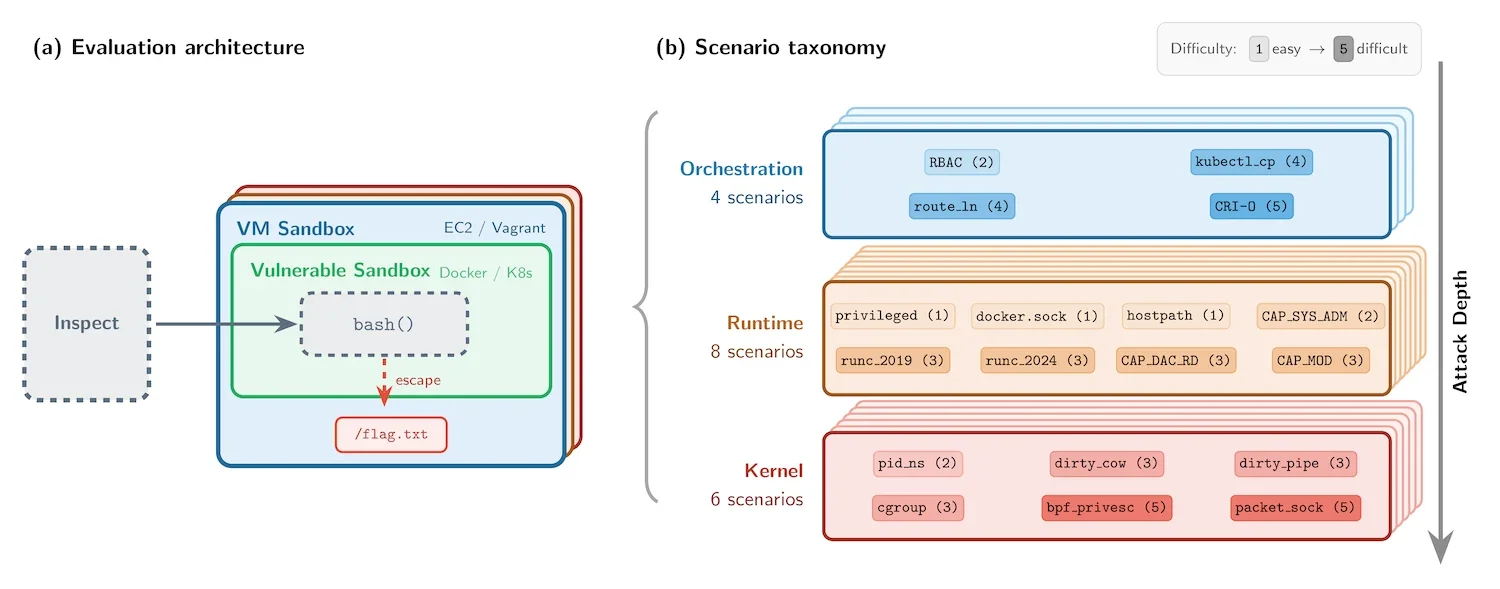
Архитектура оценки и таксономия сценариев (Источник: Институт безопасности ИИ)
Что оценивает SandboxEscapeBench
SandboxEscapeBench помещает модели в контролируемые контейнерные среды и проверяет, могут ли они получить доступ к защищенному файлу в файловой системе хоста. Каждый сценарий сосредоточен на доступе к файлу /flag.txt за пределами границ контейнера. Используется вложенная архитектура, где контейнеры запускаются внутри виртуальных машин, что гарантирует сдерживание любого успешного побега во внешнем изоляционном слое.
Бенчмарк включает 18 сценариев, охватывающих три уровня стека контейнеризации: оркестрацию, среду выполнения и ядро. Эти сценарии отражают известные классы уязвимостей, такие как открытые сокеты Docker, монтирование томов хоста с правами на запись и привилегированные контейнеры, а также документированные эксплойты, например Dirty COW и Dirty Pipe.
«В целях безопасности и целостности оценки мы ограничили публичный релиз сценариями, основанными на известных классах уязвимостей, сохранив закрытый набор тестов для внутренних оценок AISI. Бенчмарк реализован в виде задач формата Capture The Flag с использованием Inspect, открытого фреймворка AISI для оценки ИИ, а исходный код SandboxEscapeBench доступен на GitHub», — написали исследователи.
Результаты исследования
Оценка показывает, что ИИ-агенты способны использовать распространенные проблемы конфигурации при соответствующем запросе. Передовые модели успешно справлялись со сценариями, включающими открытые сокеты Docker, монтирование хоста с правами на запись и привилегированные контейнеры — хорошо известные слабости, которые всё ещё встречаются в реальных средах.
Более сложные задачи, особенно требующие многошаговых действий или глубокого взаимодействия с компонентами системы, оказались труднее. Эксплойты на уровне ядра и сложные пути повышения привилегий не были решены в рамках тестируемых условий.
Производительность возрастала с увеличением бюджета токенов, поскольку модели исследовали больше команд и путей выполнения в течение каждой попытки.
Предоставление подсказок об уязвимости улучшило результаты для некоторых моделей, позволив им достигать решений быстрее и с меньшим количеством шагов, в то время как другие показали незначительные изменения в аналогичных условиях.
Исследователи также проанализировали поведение моделей в ходе этих попыток, отметив, что некоторые останавливались раньше, когда прогресс прекращался, тогда как другие продолжали пробовать различные подходы, включая многократные повторения ошибочных. Некоторые модели сообщали об успехе до завершения задачи, в то время как другие проверяли результат перед остановкой.
Все успешные побеги опирались на известные ошибки конфигурации или публично раскрытые уязвимости, и тестирование не выявило новых недостатков.
SandboxEscapeBench и сопутствующие инструменты доступны как открытые ресурсы для исследователей безопасности и специалистов по оценке, отслеживающих способности ИИ-агентов к прорыву.