Google TurboQuant: Экономия памяти для ИИ без потери точности

Крупные языковые модели сталкиваются с постоянной проблемой масштабирования. По мере увеличения контекстных окон, объём памяти, необходимый для хранения кэшей ключей и значений (KV), растёт пропорционально, потребляя ресурсы GPU и замедляя процесс вывода. Команда Google Research разработала три алгоритма сжатия: TurboQuant, PolarQuant и Quantized Johnson-Lindenstrauss (QJL). Все они предназначены для агрессивного сжатия этих кэшей без ущерба для качества выходных данных модели.
Проблема накладных расходов при векторном квантовании
Векторное квантование давно используется для сжатия высокоразмерных числовых представлений, обрабатываемых ИИ-моделями. Этот метод сокращает объём памяти, сопоставляя непрерывные значения с меньшими, дискретными наборами чисел. Постоянным ограничением традиционных подходов является необходимость хранения констант квантования с высокой точностью для каждого небольшого блока данных, что добавляет от одного до двух дополнительных бит на число. Для систем, уже испытывающих нехватку памяти, эти накладные расходы компенсируют значительную часть выигрыша от сжатия.
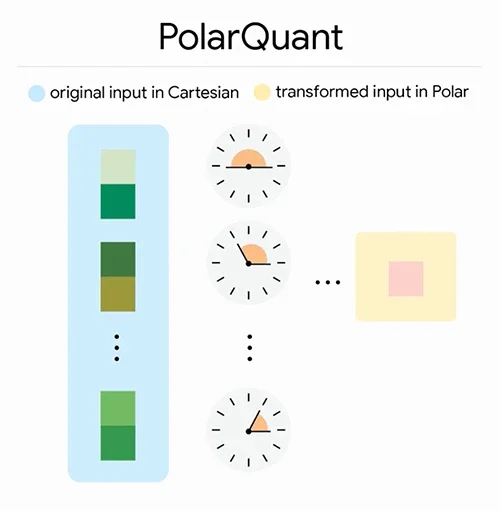
PolarQuant выступает в роли высокоэффективного моста сжатия, преобразуя декартовы входные данные в компактную полярную «стенографию» для хранения и обработки (Источник: Google Research)
TurboQuant решает эту проблему, комбинируя два базовых метода. PolarQuant выполняет первичный этап сжатия, преобразуя стандартные векторы декартовых координат в полярные координаты. Обычный квантизатор записывает положение вдоль каждой оси независимо, требуя шагов нормализации, которые варьируются в зависимости от данных. PolarQuant сопоставляет пары координат с полярной системой, выражая их как радиус и угол. Поскольку угловое распределение предсказуемо и концентрировано, метод устраняет этап нормализации и связанные с ним накладные расходы.
QJL обрабатывает остаточную ошибку. Используя преобразование Джонсона-Линденштраусса, QJL сводит каждое оставшееся векторное значение к одному биту знака — положительному или отрицательному. Этот шаг не создаёт никаких дополнительных затрат памяти. Для сохранения точности при работе с однобитными представлениями QJL использует оценщик, который сопоставляет векторы запросов высокой точности с упрощёнными хранимыми данными при вычислении оценок внимания.
В Google Research описывают комбинированный результат прямо: «TurboQuant — это метод сжатия, который обеспечивает высокое уменьшение размера модели без потери точности, что делает его идеальным как для сжатия кэша ключей-значений (KV), так и для векторного поиска».
Результаты тестирования в пяти наборах данных
Исследователи Google оценили все три алгоритма на пяти бенчмарках для длинного контекста: LongBench, Needle In A Haystack, ZeroSCROLLS, RULER и L-Eval. В качестве тестовых моделей использовались Gemma и Mistral. TurboQuant сжимал KV-кэши до 3 бит на значение без необходимости дообучения или тонкой настройки модели и без измеримой потери точности в задачах ответов на вопросы, генерации кода и суммаризации.
Сокращение использования памяти достигло как минимум 6 раз по сравнению с несжатым KV-хранилищем. На GPU NVIDIA H100 4-битный TurboQuant обеспечил ускорение вычисления логитов внимания до 8 раз по сравнению с 32-битными неквантованными ключами. PolarQuant показал почти без потерь результаты в задачах поиска иголки в стоге сена.
Алгоритмы также сравнивались с современными базовыми методами векторного поиска, а именно Product Quantization (PQ) и RabbiQ. TurboQuant продемонстрировал превосходные показатели полноты на наборе данных GloVe (d=200) в задачах top-k поиска, делая это без использования больших кодовых книг и специфичной для набора данных настройки, которые требуются этим базовым методам.
Последствия для векторного поиска и инфраструктуры вывода
Команды по безопасности и инфраструктуре ИИ, работающие с крупномасштабным семантическим поиском или конвейерами вывода LLM, напрямую сталкиваются с ограничениями памяти, которые решают эти алгоритмы. Размер KV-кэша ограничивает длину контекста в промышленных развертываниях; сжатие, сохраняющее точность вывода, расширяет возможности заданного выделения GPU. Для рабочих нагрузок векторного поиска, используемых в системах поиска угроз, определения схожести документов и обнаружения аномалий, методы, сокращающие память индекса без ущерба для полноты, напрямую влияют на пропускную способность запросов в масштабе.
Исследователи Google отмечают, что TurboQuant работает независимо от данных, то есть не требует калибровки под конкретный набор данных. Это свойство упрощает интеграцию в системы вывода и сокращает необходимый конвейер предварительной обработки перед развертыванием.
Исследовательская группа называет теоретическое обоснование алгоритмов ключевым фактором их надежности. TurboQuant и его составные методы работают вблизи известных теоретических нижних границ искажения при квантовании — свойство, которое, по словам авторов, делает их надежными для крупномасштабных промышленных систем.