Искусственный интеллект порождает хаос с доступом: секреты просачиваются в код, инструменты и инфраструктуру

Код продолжает перемещаться по конвейерам, а вместе с ним продолжают всплывать и учетные данные. Отчет GitGuardian «Состояние утечки секретов 2026» оценивает количество новых хардкодированных секретов в публичных коммитах GitHub за 2025 год в 28,65 миллиона, что продолжает многолетний рост числа раскрытых ключей доступа, токенов и паролей.
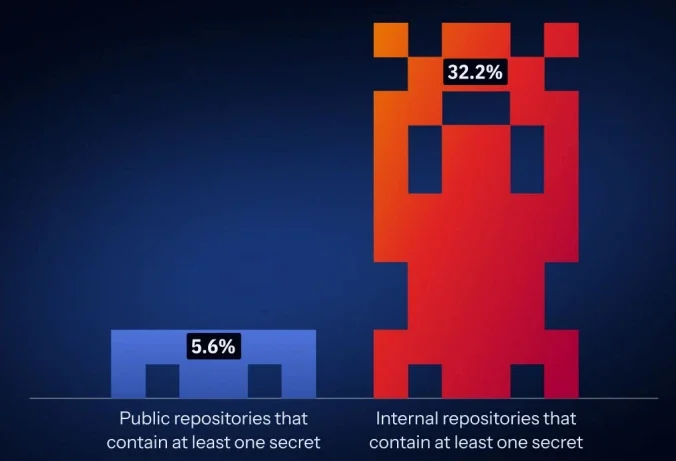
Публичные и внутренние репозитории, содержащие хотя бы один секрет (Источник: GitGuardian)
Утечки распространяются за пределы кода
Проблема больше не существует только в публичных репозиториях, поскольку на внутренние среды приходится большая доля утекших учетных данных, часто напрямую связанных с производственными системами и операционным доступом. Внутренние репозитории демонстрируют гораздо более высокую вероятность содержания хардкодированных секретов, что приближает чувствительный доступ к ключевой инфраструктуре.
Значительная доля инцидентов также возникает из инструментов вне системы контроля версий, где платформы для совместной работы, такие как Slack, Jira и Confluence, становятся частью повседневных рабочих процессов. В этих средах часто оказываются учетные данные, которыми обмениваются при устранении неполадок или рутинной координации, и эти записи могут предоставлять немедленный доступ к системам.
Самостоятельно размещаемая инфраструктура добавляет еще одно измерение: экземпляры GitLab и реестры Docker, доступные в интернете, содержат большие объемы учетных данных, которые могут оставаться работоспособными после обнаружения. Эти системы, как правило, работают вне стандартных процессов сканирования, что позволяет конфиденциальным данным накапливаться со временем.
Разработка ИИ добавляет больше учетных данных для отслеживания
Рост инструментов искусственного интеллекта привел к появлению новых источников учетных данных в рабочих процессах разработки, где проекты теперь подключаются к поставщикам моделей, уровням оркестрации, системам извлечения и фреймворкам агентов, каждый из которых требует своей собственной аутентификации и увеличивает общий объем циркулирующих секретов.
Многие из самых быстрорастущих категорий утекших секретов напрямую связаны с этими сервисами ИИ. Эти учетные данные появляются в коде, конфигурационных файлах и вспомогательной инфраструктуре. Кодирование с помощью ИИ способствует этой тенденции: сгенерированные или созданные совместно изменения демонстрируют более высокий процент раскрытых секретов по сравнению с общим базовым уровнем.
“Искусственный интеллект упрощает и ускоряет разработку, интеграцию и поставку. Однако каждый новый инструмент, API, рабочий процесс, агент и сервисный аккаунт создаёт новые учётные данные для управления и расширяет поверхность для атак. Когда организации масштабируют создание быстрее, чем управление, секреты начинают распространяться повсюду”, — написала компания в блоге.
Это демонстрирует сдвиг в средах разработки, где команды подключают больше сервисов и полагаются на автоматизацию для сборки и развёртывания программного обеспечения. Каждое подключение добавляет ещё один набор учётных данных, который необходимо хранить, передавать и обслуживать, увеличивая количество мест, где может произойти утечка.
Утекшие учётные данные остаются действительными годами
Одной из наиболее устойчивых проблем является срок, в течение которого скомпрометированные учётные данные остаются активными: секреты, утекшие несколько лет назад, продолжают работать, продлевая риск далеко за пределы первоначального инцидента.
Замена учётных данных часто требует изменений в нескольких системах, включая кодовые базы, конвейеры развёртывания и общие конфигурации. Эти зависимости замедляют исправление и позволяют скомпрометированному доступу сохраняться.
В отчёте также отмечаются пробелы в том, как команды расставляют приоритеты исправлений. Методы приоритизации, основанные только на статусе проверки, оставляют часть риска без внимания. Некоторые чувствительные учётные данные не соответствуют известным шаблонам или не могут быть проверены автоматически, но при этом предоставляют значимый доступ.
Более широкая операционная проблема
Это показывает, как учётные данные теперь перемещаются по программным системам. Они появляются в репозиториях, внутренних платформах, инструментах совместной работы и сервисах инфраструктуры. Такое распределение затрудняет отслеживание владельца, использования и фактов утечки.
Сервисы, связанные с ИИ, добавляют ещё один уровень: учётные данные появляются в файлах конфигурации, привязанных к новым стандартам, таким как MCP. Эти файлы часто находятся рядом с логикой приложения и могут быть зафиксированы вместе с кодом.
В результате формируется более крупная и фрагментированная среда, где утечки охватывают множество систем с разными средствами контроля и сроками реагирования. Учётные данные, созданные в одной части рабочего процесса, могут всплыть в другой и оставаться активными долгое время после первоначального компрометирования.
Распространение утечек секретов отражает принципы разработки и поддержки ПО в распределённых командах с использованием различных инструментов. Количество раскрытых учётных данных продолжает расти, и многие из них остаются активными в течение длительного времени. Внутренние системы, платформы для совместной работы и процессы с использованием искусственного интеллекта — всё это усугубляет данную тенденцию, расширяя как масштабы, так и продолжительность рисков, связанных с утечкой доступа.