29 миллионов утекших данных в 2025: Как учетные записи ИИ-агентов вышли из-под контроля

Искусственному интеллекту для работы требуются учетные данные. Он аутентифицируется на платформах языковых моделей, подключается к базам данных, вызывает SaaS-API, получает доступ к облачным ресурсам и координирует работу десятков внешних сервисов. Каждая точка интеграции требует своей идентификации. Большинство организаций справляются с этим плохо, и доказательства тому — в их коде.
Отчет GitGuardian о состоянии утечки секретов показал, что в 2025 году в публичных коммитах GitHub было обнаружено 28 649 024 новых секрета, что на 34% больше, чем годом ранее, и является самым большим годовым скачком за всю историю наблюдений.
Одна из коренных причин — дизайн аутентификации: какой тип учетных данных выбирается, какой объем прав они предоставляют, как долго действуют и где хранятся. Тем временем искусственный интеллект создает все больше учетных данных, требующих управления, и генерирует больше артефактов, через которые эти данные могут утечь.
Код, созданный с помощью ИИ, удваивает частоту утечек учетных данных
Самый явный сигнал о том, что управление аутентификацией не поспевает за скоростью развития ИИ, исходит от коммитов, созданных с его помощью. GitGuardian обнаружил, что коммиты, созданные с участием Claude Code в 2025 году, содержали утекшие секреты примерно в два раза чаще, чем в среднем по публичному GitHub.
Когда скорость написания кода увеличивается, вместе с ней растет и скорость создания учетных данных. Дело не в том, что какой-то конкретный ассистент особенно небрежен. Разработчики создают каркасы проектов, настраивают интеграции, тестируют API-вызовы и коммитят рабочие прототипы еще до того, как кто-либо задумается о том, где должны храниться учетные данные, кому они принадлежат и как их обновлять.
Код, сгенерированный ИИ, часто выглядит готовым к продакшену еще до того, как он таковым становится, и этот пробел заполняется жестко прописанными API-ключами.
Скорость интеграции может вырасти в 10 раз, но управление учетными данными не масштабируется с той же скоростью. Модели аутентификации, полагающиеся на ручную дисциплину разработчиков, не выдерживают скорости работы с ИИ.

Интеграция с несколькими провайдерами умножает поверхности для утечки данных
В отчете было обнаружено более 1,2 миллиона утекших секретов, связанных с AI-сервисами, в 2025 году, что на 81% больше, чем годом ранее. Двенадцать из пятнадцати самых быстрорастущих типов утекших секретов были связаны с сервисами искусственного интеллекта. Это отражает реальный процесс разработки: быстро, с использованием нескольких провайдеров, где рабочий код приоритетнее управления учетными данными.
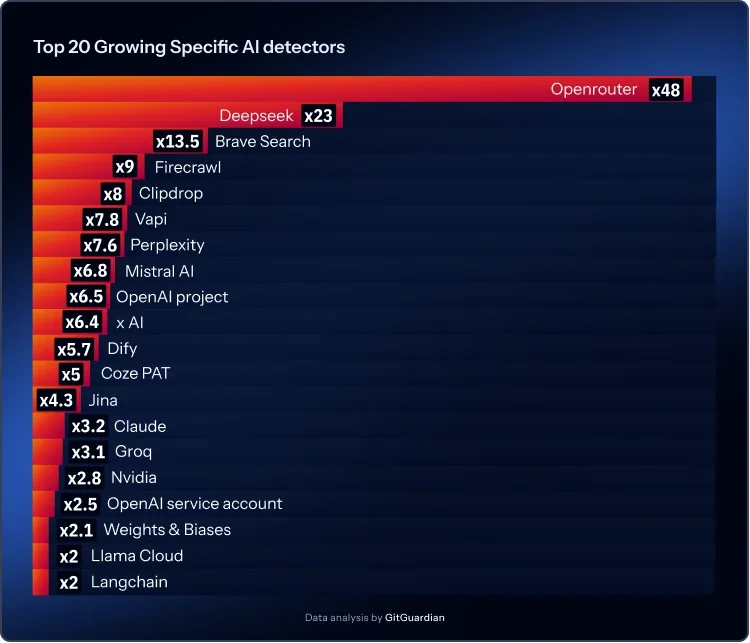
Интеграция с несколькими поставщиками становится стандартной практикой. Команды подключаются к нескольким платформам языковых моделей для повышения отказоустойчивости и подбора возможностей. Один сервис, OpenRouter, выступающий шлюзом к множеству моделей через единый API, столкнулся с ростом утечек учетных данных более чем в 48 раз в годовом исчислении. Теперь проекты в сфере ИИ обычно зависят от нескольких поставщиков моделей, а не от одного.
Больше поставщиков означает больше типов учетных данных на проект, больше поверхностей интеграции для защиты и больше возможностей для распространения статических API-ключей. Отдельные поставщики моделей демонстрировали схожие тенденции. Новые участники рынка, такие как Deepseek, показали взрывной рост, в то время как устоявшиеся платформы продолжали стабильно расширяться. Модель аутентификации не эволюционировала в соответствии с этой новой многопровайдерской реальностью.
Открытые платформы моделей, такие как Hugging Face, сохраняли объемы утечек на уровне свыше 130 000 ежегодно, практически без изменений по сравнению с предыдущим годом. Эта стабильность означает, что команды не решили базовую проблему. Платформы для инференса, которые помогают командам эффективно запускать модели с открытым исходным кодом, быстро растут, но они перенимают те же небезопасные шаблоны работы с учетными данными, которые существовали и раньше.
Полный стек ИИ требует аутентификации на каждом уровне
Системы ИИ — это полноценные приложения, требующие оркестрации, мониторинга, работы с данными, поиска и извлечения информации. Каждому уровню нужна аутентификация, и на каждом уровне наблюдается тот же разрыв в управлении доступом.
Платформы баз данных, разработанные для ИИ-приложений, особенно те, что поддерживают векторный поиск, показали рост числа утечек почти на 1000% в годовом исчислении. Эти платформы позволяют быстро развернуть рабочие приложения, и именно в такие моменты разработчики прибегают к удобным, но небезопасным учетным данным вместо правильно настроенных сервисных аккаунтов.
Фреймворки оркестрации, помогающие разработчикам объединять модели, инструменты и рабочие процессы, показали примерно двукратный рост утечек. Платформы для отслеживания экспериментов и мониторинга моделей демонстрировали схожую картину. Каждый скомпрометированный ключ соответствует интеграции, в которой скорость была приоритетнее надлежащего разграничения прав доступа.
Слои поиска и извлечения данных продемонстрировали взрывной рост. Сервисы, которые направляют запросы через поисковые API, подают контекст в модели или предоставляют веб-поиск, на который могут ссылаться ИИ-системы, стали появляться в утекших учетных данных с резко возросшей частотой. Платформы голосовой инфраструктуры для ИИ-агентов выросли почти на 800%, что показывает переход ИИ в клиентские сценарии, такие как голосовая поддержка и продажи, где каждая интеграция вносит новые учетные данные в повседневные репозитории.
Платформы для создания агентов, которые помогают командам строить агентные системы без написания оркестрации с нуля, показали темпы роста от 500% до 600%. Эти платформы особенно рискованны, так как их токены доступа часто имеют широкие разрешения на уровне аккаунта, открывая доступ не к одному сервису, а ко всей сети делегированных интеграций.
Закономерность для всех этих сервисов едина: удобные учетные данные создаются при интеграции, редко получают правильное ограничение прав и утекают, когда ИИ-системы генерируют именно те артефакты, в которых секреты появлялись исторически.
Новые стандарты закрепляют небезопасные практики
Исследование GitGuardian по Model Context Protocol показывает, как новые стандарты интеграции могут распространять небезопасные методы аутентификации. MCP появился в начале 2025 года как способ подключения больших языковых моделей к внешним инструментам и источникам данных. В исследовании было обнаружено 24 008 уникальных секретов, раскрытых в конфигурационных файлах MCP.
Типы утекших учетных данных напрямую соответствуют слою поддержки ИИ: поисковые API, сервисы извлечения данных, доступ к базам данных и внешние интеграции. Ключи API Google составили почти 20% раскрытых секретов, строки подключения к PostgreSQL — 14%, а сервисы поиска и извлечения данных заняли оставшуюся часть.

Новые стандарты распространяются через примеры. Разработчики копируют образцы конфигураций, адаптируют их и развертывают. Если эти примеры демонстрируют аутентификацию через жёстко заданные учетные данные в локальных файлах, эта модель становится де-факто реализацией. MCP не является уникально ущербным. Это типичная ситуация. Новые интерфейсы интеграции по умолчанию используют статические секреты в конфигурационных файлах, пока кто-то не заставит применить лучший подход.
Что на самом деле требует управление аутентификацией в ИИ
Обнаружение фиксирует утечки после того, как они произошли. Решение находится выше по течению: проектирование аутентификации, которое изначально предотвращает создание учетных данных небезопасным способом.
Искусственные интеллекты должны рассматриваться как управляемые нечеловеческие сущности. Каждому агенту требуется собственная уникальная идентичность, ограниченные права доступа, назначенный владелец и включение в процессы переаттестации управления доступом. Общие учётные данные уничтожают возможность атрибуции и сводят на нет способность реагировать на инциденты. Машинные идентичности превосходят человеческие в соотношении 45:1 в большинстве компаний, и искусственный интеллект ускоряет этот дисбаланс без соответствующего развития систем управления.
Статические секреты должны быть заменены на краткосрочные учётные данные. Для интеграций с SaaS-сервисами по умолчанию следует использовать OAuth 2.1 с делегированным доступом. Для облачных рабочих нагрузок федерация удостоверений рабочих нагрузок или управляемые идентичности полностью исключают хранение статических ключей. API-ключи следует применять только при отсутствии более надёжного механизма и исключительно под строгим контролем: хранение в защищённом хранилище, уникальный ключ для каждого агента, обязательное ограничение срока действия и постоянный мониторинг на предмет утечки.
Жизненный цикл учётных данных должен управляться событиями, а не календарём. Смена ключей должна запускаться при обновлениях развёртывания, изменениях конфигурации, модификации прав доступа или обнаружении аномалий. Каждая автономная система обязана иметь проверенную возможность отзыва прав. Разница между локализованным нарушением и системным компромиссом заключается в том, можно ли отозвать доступ за минуты или же на это уходят часы.
Данные GitGuardian о нарушениях политик показывают главную проблему: долгоживущие секреты составляют 60% всех нарушений. Внутренние утечки секретов — 17%, дублирование ключей — 16%. Основная проблема — халатность в управлении жизненным циклом. Секреты существуют слишком долго, распространяются слишком широко и копируются быстрее, чем ими успевают управлять.

Разрыв в скорости
Искусственный интеллект упрощает создание программного обеспечения. Когда ускоряется разработка ПО, с той же скоростью растёт и создание новых идентичностей. Когда идентичности множатся быстрее, секреты распространяются скорее, чем механизмы управления могут адаптироваться.
Командам безопасности необходимы ответы на базовые вопросы: Кто создал эту идентичность? К чему у неё есть доступ? Когда срок её действия истекает? Большинство организаций сегодня не могут ответить ни на один из этих вопросов для своих ИИ-агентов. Эти 29 миллионов утекших секретов представляют собой фундаментальные сбои: решения по аутентификации, принятые ради удобства и затем масштабированные с помощью ИИ-разработки.
Удвоенная частота утечек в коммитах с использованием ИИ — это не пробел в сканировании и не недостаток обучения разработчиков. Это архитектурная проблема. Современные модели аутентификации предполагают интеграцию в человеческом темпе с ручными контрольными точками управления. ИИ устраняет эти естественные замедления. Организациям необходимо либо перестроить управление аутентификацией под скорость ИИ, либо они будут накапливать риски, связанные с учётными данными, быстрее, чем смогут их обнаружить.