Внедрение ИИ опережает меры безопасности

Искусственный интеллект становится частью как профессиональной, так и личной жизни, достигая массового распространения быстрее, чем персональный компьютер или интернет. Эти системы теперь проходят проверку на логику, безопасность и выполнение практических задач, однако надёжность подобных измерений остаётся под вопросом.
Индекс ИИ за 2026 год от Стэнфордского института человеко-ориентированного искусственного интеллекта описывает общую среду, в которой происходит этот рост, включая экономическую ценность, влияние на рынок труда и роль технологического суверенитета в области ИИ. В отчёте также рассматриваются достижения в науке и медицине, исчерпание традиционных тестовых наборов и системы управления, которые не успевают адаптироваться. Глобальные настроения отражают эту картину: растущий оптимизм соседствует с сохраняющейся нервозностью.
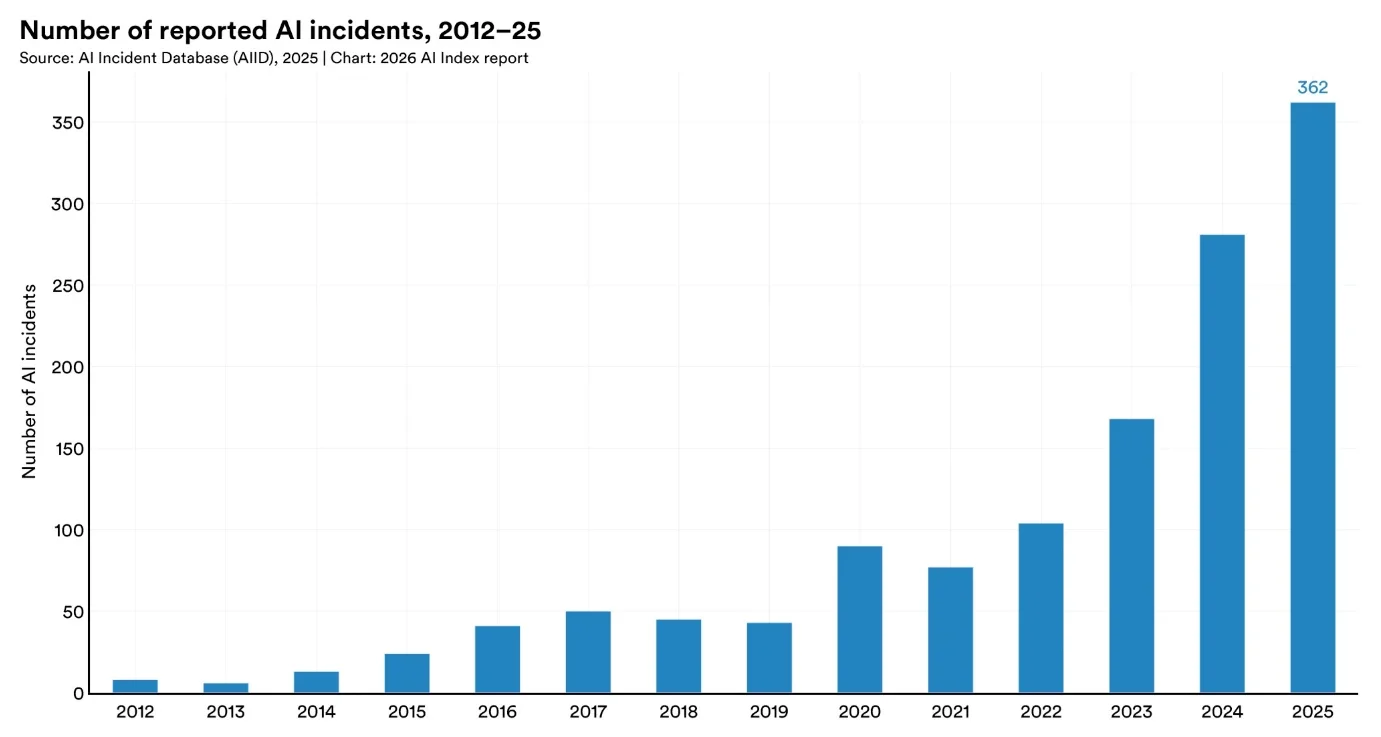
Количество зафиксированных инцидентов с ИИ, 2012-25 гг. (Источник: Stanford HAI)
Количество инцидентов продолжает расти
Число зарегистрированных инцидентов, связанных с искусственным интеллектом, увеличилось за последний год, что отражает более широкое присутствие этих систем в реальных условиях. База данных AI Incident Database зафиксировала 362 инцидента в 2025 году по сравнению с 233 в 2024 году. Аналогичную тенденцию показывает отдельный проект мониторинга ОЭСР: ежемесячное количество инцидентов достигло 435 в начале 2026 года и стабильно держится в среднем выше 300 в последние месяцы.
Эти цифры охватывают широкий спектр проблем: от непреднамеренных результатов работы систем до их неправомерного использования и сбоев в эксплуатации. Системы, работающие в каналах взаимодействия с клиентами или во внутренних автоматизированных процессах, теперь функционируют в таких масштабах, что даже небольшие ошибки быстро проявляются и могут наблюдаться в различных средах. Статистика отражает эту экспозицию: по мере расширения внедрения всё больше случаев попадает в публичные или частично публичные отчёты. Команды, ответственные за мониторинг таких систем, работают с растущим потоком сигналов, требующих сортировки, классификации и реагирования.
Во многих случаях эти инциденты не следуют знакомым шаблонам, характерным для программных сред. Результаты работы ИИ могут меняться в зависимости от контекста, формулировки запроса или истории взаимодействия, что затрудняет воспроизведение и анализ проблем. Это добавляет сложности процессу реагирования на инциденты, где командам приходится интерпретировать поведение системы, которое не всегда чётко соответствует определённым состояниям сбоя.
Доступ к моделям становится более контролируемым
Способ выпуска ИИ-моделей сместился в сторону ограниченного доступа. Наиболее заметные модели теперь исходят от индустрии, и многие предоставляются через API, которые ограничивают взаимодействие пользователей с ними. Среди моделей, отслеживаемых в 2025 году, выпуск на основе API был наиболее распространённым подходом, определяющим интеграцию этих систем в рабочие процессы организаций.
Код обучения редко публикуется. Большинство моделей выпускаются без кода, использованного для их создания, и лишь небольшое число делает этот код общедоступным. Это ограничивает возможности внешних команд воспроизводить результаты, изучать методы обучения или тестировать системы вне условий, определённых их разработчиками. Это также сужает область независимой проверки, которая исторически играла роль в выявлении слабостей или неожиданного поведения.
Ограниченный доступ также влияет на то, как организации оценивают поставщиков и инструменты перед внедрением. Без видимости процессов обучения или архитектуры модели оценка часто фокусируется на наблюдаемой производительности и задокументированном поведении. Это смещает акцент на тестирование во время интеграции и на мониторинг после ввода систем в эксплуатацию.
Показатели прозрачности снижаются
Общий уровень раскрытия информации о базовых моделях снизился. Индекс прозрачности базовых моделей упал со среднего значения 58 в 2024 году до 40 в 2025 году. Более низкие баллы наблюдаются в категориях, связанных с тем, как модели создаются и что происходит после их развёртывания, включая источники данных, вычислительные ресурсы и последующее воздействие.
Это влияет на то, как организации оценивают системы, которые они внедряют. Информация о том, как получить доступ к модели, часто доступна через документацию и интерфейсы, в то время как детали о данных обучения, ограничениях системы или долгосрочных эффектах раскрываются реже. Этот дисбаланс создаёт пробелы в информации, необходимой для оценки рисков и управления, особенно когда системы интегрируются в критически важные процессы.
Сокращение раскрытия информации также ограничивает возможность сравнивать системы за пределами поверхностных характеристик. Команды могут полагаться на частичную документацию или сторонний анализ, чтобы понять различия между моделями, что может внести неопределённость в решения по выбору и внедрению.
Тестирование возможностей остаётся более заметным, чем тестирование безопасности
Разработчики моделей продолжают публиковать результаты на тестовых наборах, которые измеряют способности к рассуждению, программированию и выполнению общих задач. Эти оценки широко используются и служат общей точкой отсчёта для сравнения возможностей различных систем.
Тесты, связанные с безопасностью, освещаются менее последовательно и охватывают более узкий набор моделей. Категории, изучающие вредоносные выводы, предвзятость или сценарии злоупотребления, встречаются в меньшем числе отчётов и не имеют единой структуры представления. Такое неравномерное покрытие снижает возможность сравнивать системы по их поведению в условиях риска, даже когда тесты на возможности общедоступны. На практике команды, оценивающие ИИ-системы, часто комбинируют ограниченные опубликованные данные с собственным внутренним тестированием.
«На техническом фронте ведущие модели теперь почти неотличимы друг от друга. Модели с открытыми весами стали как никогда конкурентоспособными. Но по мере сближения моделей инструменты для их оценки отстают и теряют актуальность. Тестовые наборы насыщаются, ведущие лаборатории раскрывают меньше информации, а независимое тестирование не всегда подтверждает заявления разработчиков», — заявили Йоланда Гил и Рэймонд Перро, сопредседатели отчёта AI Index.
Практики надзора адаптируются к ограниченной видимости
Системы искусственного интеллекта интегрируются в рабочие процессы, которые изначально не были предназначены для автономного принятия решений или вероятностных выводов. Это создаёт новые требования к процедурам надзора, особенно в областях, где системы взаимодействуют с пользователями, генерируют контент или влияют на операционные решения.
Команды по безопасности и управлению рисками адаптируются, уделяя больше внимания непрерывному мониторингу и внутренней валидации. Во многих случаях оценка не полагается исключительно на опубликованные тесты. Организации создают собственные тестовые среды, чтобы наблюдать за поведением моделей в конкретных условиях, соответствующих их операционной деятельности.
Команды разрабатывают процессы для классификации и реагирования на инциденты, связанные с ИИ, которые не вписываются в такие категории, как программные ошибки или уязвимости безопасности. Эти инциденты могут включать неоднозначные выводы, неожиданное поведение модели или взаимодействия, приводящие к непреднамеренным результатам без чётко определённой точки сбоя.
Отношения с поставщиками также меняются в этих условиях. Когда доступ к деталям базовой модели ограничен, организации всё больше полагаются на договорные условия, контроль использования и ожидания по уровню сервиса для определения ответственности. Это повышает важность того, как модели развёртываются и отслеживаются после интеграции, уделяя меньше внимания тому, как они изначально разрабатывались.
Эти изменения отражают более широкий переход в управлении системами ИИ в производственных средах. Надзор становится непрерывным процессом, связанным с поведением системы в процессе эксплуатации, формируемым внутренним контролем и операционным опытом, а не внешней видимостью в дизайн модели.